eHive development in a nutshell
Repository structure
The ensembl-hive repository has a similar structure to the other Ensembl
repositories (modules, DBSQL, scripts).
|-- docker # Everything related to Docker, especially the Dockerfile
|-- docs # The user manual (mostly RestructuredText documents)
|-- modules # Perl modules, all under the Bio::EnsEMBL::Hive namespace
| `-- Bio
| `-- EnsEMBL
| `-- Hive
| |-- DBSQL # Object adaptors
| |-- Examples # Example PipeConfigs and Runnables
| |-- Meadow # Default meadow implementations
| |-- PipeConfig # Base class for PipeConfigs
| |-- RunnableDB # Default set of Runnables
| |-- Scripts
| `-- Utils
|-- scripts # Public scripts
| `-- dev # Internal scripts
|-- sql # Schema definition files and SQL patches
|-- t # Test suite
| |-- 01.utils
| |-- 02.api
| |-- 03.scripts
| |-- 04.meadow
| |-- 05.runnabledb
| `-- 10.pipeconfig
`-- wrappers # Wrappers for other languages
`-- python3
eHive vs Ensembl
eHive is completely independent from the Ensembl Core API (since version 2.0), but it still exhibits several links.
When the Registry is present, all the adaptors will be recorded there (under the group hive), but eHive doesn’t need the Registry to get data adaptors: eHive data adaptors are kept under their DBAdaptor. eHive still knows that Ensembl databases are often referred to by species and type, and will use the Registry in those cases (which can be loaded from a configuration file).
DBSQL::CoreDBConnection is mostly a copy of Core’s
DBSQL::DBConnection, but both files are now diverging slightly. When
the latter is available, the former will inherit from it, thus maintaining
compatibility for programs that check that the connection object as the
Core type. eHive has developed new functionalities in its own
DBSQL::DBConnection, and has reimplemented DBSQL::StatementHandle
to allow catching connection errors and automatically reconnecting.
In summary, eHive connections are protected against:
“MySQL server has gone away” errors through:
a reimplementation of
DBSQL::StatementHandle(which allows code to be entirely compatible with the Core API)allowing to call dbh methods on the connection object itself (whilst capturing the error), though this requires the calling code to be updated. In hindsight, it would have been better to implement a new class
DBSQL::DatabaseHandlethat would wrap and protect db_handle calls the same wayDBSQL::StatementHandlewraps and protects sth calls.Note
$dbc->db_handle->prepareis protected by calling$dbc->protected_preparebecauseDBConnection::prepare()already exists.
Deadlocks and “Lock wait timeout” errors through a new
protected_prepare_executemethod that combinesprepareandexecute.protected_prepare_executehas to be explicitly called, and is currently only used in critical statements (usually revolving around job semaphores, statuses and log messages.
Custom ORM
Adaptors
eHive has its own, home-made, ORM. The base class BaseAdaptor
implements all the database-related methods. Your new adaptor will very
likely inherit from one of its two subclasses: NakedTableAdaptor or
ObjectAdaptor. The former deals with unblessed hashes, while the latter
deals with objects (blessed hashes).
eHive adaptors can automatically do many things (as we will see below) but they are by design limited to operating on a single table. This means that the eHive API has a 1-to-1-to-1 mapping between tables, adaptors and objects.
The basic bricks exposed by BaseAdaptor are:
count_allcounts the number of rows in the table given a certain constraint.fetch_allfetches some rows in the table given a certain constraint.fetch_by_dbIDfetches one object by its primary key.remove_allremoves some rows in the table given a certain constraint.removeremoves a particular object.store_or_update_onewill automatically run one of these:storeto add a new object to the databaseupdateto update an object in the database
BaseAdaptor has an AUTOLOAD that understands many variants of
count_all, fetch_all, remove_all and update:
Filtering:
fetch_by_name,fetch_by_analysis_id_AND_input_id,fetch_all_by_role_id_AND_status,count_all_by_from_analysis_id_AND_branch_code,remove_all_by_param_nameLimiting:
update_status,update_attempted_jobs_AND_done_jobsTransformation:
fetch_by_analysis_data_id_TO_datafetches the columndatafor a givenanalysis_data_id(returning the first row).fetch_by_data_AND_md5sum_TO_analysis_data_idfetches the columnanalysis_data_idfor a given pair (data,md5sum) (returning the first row).fetch_by_a_multiplier_HASHED_FROM_digit_TO_partial_productproduces a hash associatingdigittopartial_productfor all the rows found matchinga_multiplier(only one value perdigitis kept).fetch_all_by_job_id_AND_param_value_HASHED_FROM_origin_param_id_TO_param_nameproduces a hash associatingorigin_param_idto a list ofparam_namefor all the rows matching the pair (job_id,param_value).
As a result, adaptors can be very short (see ResourceClassAdaptor).
At the minimum they need to:
Inherit from the right class (
ObjectAdaptororNakedTableAdaptor).Define the table they deal with.
The class of objects they create (if they inherit from
ObjectAdaptor).
Then they will implement methods that cannot be expressed with the syntax
understood by AUTOLOAD (see SemaphoreAdaptor and
AnalysisAdaptor), or that need a more meaningful name (see
BeekeeperAdaptor::find_live_beekeepers_in_my_meadow).
Note
You will also need to register your adaptor in %DBAdaptor::adaptor_type_2_package_name.
Objects
Objects that are assigned an automatically-increment database ID (dbID)
must inherit from Storable.
Storable comes with a convenient AUTOLOAD that associates
object-attributes with dbID-attributes. For instance, if the
analysis attribute is defined, you can call analysis_id and
AUTOLOAD will return the dbID of the analysis. Reciprocally, if the
analysis_id attribute is set and you call analysis, AUTOLOAD will
fetch (or find, see the concept of Collections below) the Analysis object
with the given dbID.
As a result, objects don’t need to implement getters/setters for
Storable-inherited fields. For instance ResourceDescription only has
getters/setters for meadow_type, submission_cmd_args, etc, but not
resource_class and resource_class_id, because these automatically
come with AUTOLOAD.
Note
It is good practice to implement toString in every class.
HivePipeline and collections
eHive implements a caching layer that serves two purposes:
Objects don’t always live in the database. This is the case when building a pipeline from a PipeConfig (either for init_pipeline.pl or generate_graph.pl with the
--pipeconfigparameter) or when running a Job in standalone mode (and maybe one day, whole pipelines too!).Fetching from the database has a cost, that is particularly visible when the database is busy.
The cache is implemented with a couple of objects and concepts:
Utils::Collectionis a very crude implementation of a collection. At the moment it is a simple list (meaning that all operations are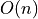 !), but this could be improved by using lookup tables instead.
Collections have methods to search, add and remove objects. They
also implement a trash-bin (dark-collection) which allows buffering
operations in memory before pushing them to the database, or even
undeleting objects. The
!), but this could be improved by using lookup tables instead.
Collections have methods to search, add and remove objects. They
also implement a trash-bin (dark-collection) which allows buffering
operations in memory before pushing them to the database, or even
undeleting objects. The find_one_by/find_all_bymethods understand a complex language that is the base for Analyses pattern syntax.HivePipelineis an object that glues together all the components of a pipeline (analyses, dataflows, etc). An instance ofHivePipelinemay have anhive_dba(aDBAdaptor).URLFactoryandTheApiaryensure that each pipeline/database is only present once in memory.HivePipelinekeeps a collection for each component type (thecollection_ofmethod).All objects that are intended to be used in a Collection should inherit from either
StorableorCacheable, which is the parent class ofStorable. Especially,HivePipelinerequires objects to implementunikeyas a way of replicating on the software side SQL UNIQUE KEY.
Both Storable and ObjectAdaptor are aware of the caching layer,
and all the relevant objects and adaptors are expected to be linked back to
the pipeline with hive_pipeline, which allows fetching and linking
through collections.
Schema changes
Each schema change is supposed to bring in the same commit several things:
a tag
sql_schema_NNN_startwith the auto-incremented schema version,the new schema for all drivers (
tables.*),patches for all relevant drivers (
patch_YYYY-MM-DD.*). They must check that the database version is n-1 before applying the changes. You can usescripts/dev/create_sql_patches.plto create template files.the API change (adaptor and object).
You then need to update guiHive. This is done by registering the new
version in the deploy.sh script. If the current guiHive code is
compatible with the new schema, you can associate both. Otherwise you will
have to create a new db_version/NNN in guiHive.
Internal versioning
eHive has a number of interfaces, that are mostly versioned. You can see
them by running beekeeper.pl --versions:
CodeVersion 2.7.0
CompatibleHiveDatabaseSchemaVersion 96
MeadowInterfaceVersion 5
Meadow::LOCAL 5.0 available
Meadow::LSF 5.2 unavailable
Meadow::SLURM 5.5 available
GuestLanguageInterfaceVersion 5
GuestLanguage[python3] 5.0 available
CodeVersion is the software version (see how it is handled in the section below).
CompatibleHiveDatabaseSchemaVersion is the database version. This is the version that matters. Most of the scripts will refuse to run on a database that comes from a different version.
MeadowInterfaceVersion is the major version of the Meadow interface. It follows semantic versioning, e.g. is incremented whenever an incompatible change is introduced. Meadows with a different major version number are listed as incompatible.
The interface for guest languages is versioned in a similar manner. GuestLanguageInterfaceVersion is the major version number, and is incremented whenever an incompatible change is introduced. GuestLanguage wrappers with a different major version number are listed as incompatible.
Releases, code branching and GIT
There are three kinds of branches in eHive:
version/X.Y.Zrepresent released versions of eHive. They are considered stable, i.e. are feature-frozen, and only receive bug-fixes. Schema changes are prohibited as it would break the database versioning mechanism. Users on a givenversion/X.Y.Zbranch must be able to blindly update their checkout without risking breaking anything. It is forbidden to force push these branches (they are in fact marked as protected on Github).mainis the staging branch for the next stable release of eHive. It receives new features (incl. schema changes) until we decide to create a newversion/X.Y.Zbranch out of it. Likeversion/X.Y.Z,mainis protected and cannot be force-pushed.experimental/XXXare where experimental features are being developed. These branches can be created, removed or rebased at will. If you base your developments on someone else’s experimental branch, let them know in order to coordinate those changes!
When a bug is discovered, it should be fixed on the oldest stable branch it
affects (and that is still actively maintained), and then cascade-merged
right up to main, e.g. version/2.3 is merged into version/2.4, which
is then merged into main. Some merges may fail because of conflict with other
commits, some bugs have to be fixed differently on different branches. If
that is the case, either fix the merge commit immediately, or do a merge
for the sake of it (git merge -s ours) and then add the correct
commits. Forcing merges to happen provides a clearer history and
facilitates tools like git bisect.
This is however the historical way. Since eHive version 2.7, all the older versions are deprecated and not maintained anymore.
Experimental branches should be rebased onto main just before the final merge (which then becomes a fast-forward). Together with the above rules, this keeps the history as linear as possible.
All changes should be done on an experimental branch or fork, and submitted as a pull request. Maintainers will bring in the pull request using GitHub’s “Rebase and merge” option. If the pull request is on a branch other than main, the maintainers will coordinate the subsequent cascade-merge up to main.
guiHive follows very similar rules:
db_version/NNNrepresent code introduced with the version NNN of the database schema. As the guiHive implementation is entirely internal, we can release new features on existingdb_version/NNNbranchesserverrepresent the main HTTP server. It doesn’t really have to change unless when a new database version is registered indeploy.sh.masteris not used any more. Do not touch it! It points at a much earlier version of guiHive where the various version-specific implementations were all mixed in the source tree rather than being on different branches.
When pushing changes, also do a cascade-merge (see above).
Continuous integration
Regressions are controlled using the test-suite (which runs on Travis CI). New developments should be tested (if not with unit tests, at least by running integration tests, e.g. a Beekeeper). Exceptions are made for situations that cannot be replicated in a test environment, e.g. massive parallelism, compute clusters, etc.
Code coverage can be examined on codecov.io, which often much better views than the other tool used in Ensembl: Coveralls. Python code can be analysed on Code Climate.
Finally, GitHub automatically triggers new builds of the documentation (here, on ReadTheDocs) and the Docker images.
Code guidelines
There are very few rules when writing new code:
For indentation use four spaces, not tabs.
Only use ASCII characters. The only exception at the moment are
Analysis.pmandHivePipeline.pmwhich are used for the Unicode Art output of generate_graph.pl, but they are meant to be replaced with character names (resp. code points), e.g.\N{BOX DRAWINGS DOUBLE UP AND RIGHT}(resp.\N{U+255A}).Use snake_case for subroutine and variable names, CamelCase for class names.
When updating code, try to keep the changes minimal, avoiding white-space changes when possible. You can also consider breaking the four-spaces rule if you can avoid changing the indentation of a massive code block. Obviously, this does not apply to languages and documents where the indentation matters (Python, reStructuredText, etc).
All the scripts should work without the user having to setup PATH or
PERL5LIB. They need to assume a default installation, with both
scripts/ and modules/ at the root of the repository.
EHIVE_ROOT_DIR can also be set to prevent this automatic discovery.